
Per capire il futuro prossimo della lotta all’evasione fiscale bisogna, forse, fare appello agli scrittori di fantascienza. Viene in mente Philip K. Dick e il suo Minority Report, da cui è stato tratto un omonimo film di successo interpretato da Tom Cruise. Anno 2054, la sezione “Precrimine” di Washington ha il potere di prevedere i crimini. Arrestare un ladro o un criminale prima che compia il delitto. Il direttore dell’Agenzia delle Entrate, Ernesto Maria Ruffini, preferisce citare un altro grande scrittore di fantascienza, Isaac Asimov. In un libro scritto nel 2013 «L’evasione spiegata a un evasore: anche a quello dentro di noi», Ruffini spiegava che l’unica possibilità è quella di «puntare ad utilizzare le banche dati esistenti in modo razionale. Abbiamo», diceva già sei anni fa, «una quantità enorme di dati a disposizione. Il problema è saperli leggere, collegarli». E citando proprio Asimov ammoniva che una volta raccolti, i dati devono «essere correlati e accostati secondo tutte le relazioni possibili». Ma Dick e Asimov vedevano questo futuro in un tempo più remoto. La verità è che qualcosa di simile alla “Precrimine” di Minority Report sta già bussando alle porte, almeno per quanto riguarda la lotta all’evasione.
IL PIANO
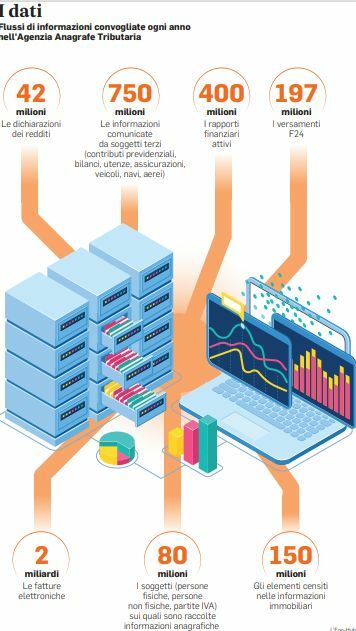
L’Unione europea finanzierà con 900 milioni di euro il progetto dell’Agenzia delle entrate per contrastare l’evasione fiscale utilizzando l’intelligenza artificiale. Gli oltre 3 miliardi di dati e informazioni che l’Agenzia raccoglie ogni anno, dalle dichiarazioni precompilate, alle fatture elettroniche, passando per le informazioni dei conti correnti e delle carte di credito, saranno vagliati da un sistema automatico, in grado di tenere sotto controllo le azioni dei contribuenti che sono a maggior rischio di evasione o elusione fiscale. Verranno usati gli strumenti della network analysis, del machine learning e dei data visualization. La network analysis permetterà di evidenziare relazioni indirette e nascoste tra le società operanti, al fine di eludere o evadere le tasse. Il machine learning consentirà agli algoritmi impiegati dall’Agenzia di imparare dalle operazioni già svolte e migliorare la propria efficienza, mentre la data visualization fornirà rappresentazioni grafiche delle analisi svolte dall’intelligenza artificiale ai funzionari dell’agenzia. Alla fine, insomma, l’Agenzia sarà in grado di capire se un determinato soggetto non solo è un evasore, ma se potenzialmente può esserlo. Il machine learning, per esempio, realizza algoritmi di apprendimento automatico che traggono conoscenza dai dati, con lo scopo di eseguire predizioni. L’Agenzia potrà aumentare la capacità di identificare e comprendere appieno fenomeni interessanti, sulla base dell’enorme patrimonio di conoscenza generata e raccolta nel tempo, con particolare riferimento al contrasto alle frodi, all’evasione e all’elusione fiscale. Il progetto partirà entro giugno 2021, la durata prevista è di 16 mesi.
CRITERI
Quanto invece al principio di imputabilità, questo trova fondamento nella necessità di garantire che sia sempre individuato un soggetto (persona fisica) responsabile, a cui possano essere ricondotti gli effetti dell’azione amministrativa adottata dall’algoritmo. Tema questo affrontato anche nella Carta della Robotica del febbraio 2017 del Parlamento Europeo, in cui sono stati analizzati proprio i criteri di imputazione della responsabilità in caso di uso di sistemi di intelligenza artificiale. E quindi, nel “vademecum” del Consiglio di Stato, l’adozione degli algoritmi nelle decisioni amministrative deve garantire: il diritto di ciascuno a conoscere l’esistenza di processi decisionali automatizzati che lo riguardino e ricevere informazioni sulla logica utilizzata; il principio di non esclusività della decisione algoritmica; e il principio di non discriminazione algoritmica, nel senso che l’algoritmo non deve assumere decisioni che abbiano effetti discriminatori verso determinati soggetti. In base a tale ultimo principio è in particolare opportuno che il titolare del trattamento utilizzi procedure matematiche o statistiche appropriate per la profilazione, mettendo in atto misure adeguate perché siano rettificati i fattori che comportano inesattezze dei dati e sia minimizzato il rischio di errori, impedendo, tra l’altro, effetti discriminatori. Per difendersi insomma dall’algoritmo non bisognerà cercare, i “precog” e il rapporto di minoranza come nel romanzo di Dick. Dovrà esserci sempre un essere umano responsabile del procedimento al quale appellarsi. Un ancoraggio alla realtà della fantascienza.